Langage Model Performance Plateaus. What’s next?

A special credit to t3dotgg (2024) for the video that inspired me to write this post before writing a post on the technical innovations behind small / more efficient language models.
This post does not constitute a journal-level review. Therefore, my research for this post was intended to be informational and did not exhaust the search space. If you notice any key papers or references that I have missed or if I misinterpreted the findings of any reference, please let me know in the comments.
Language Model Performance is Plateauing
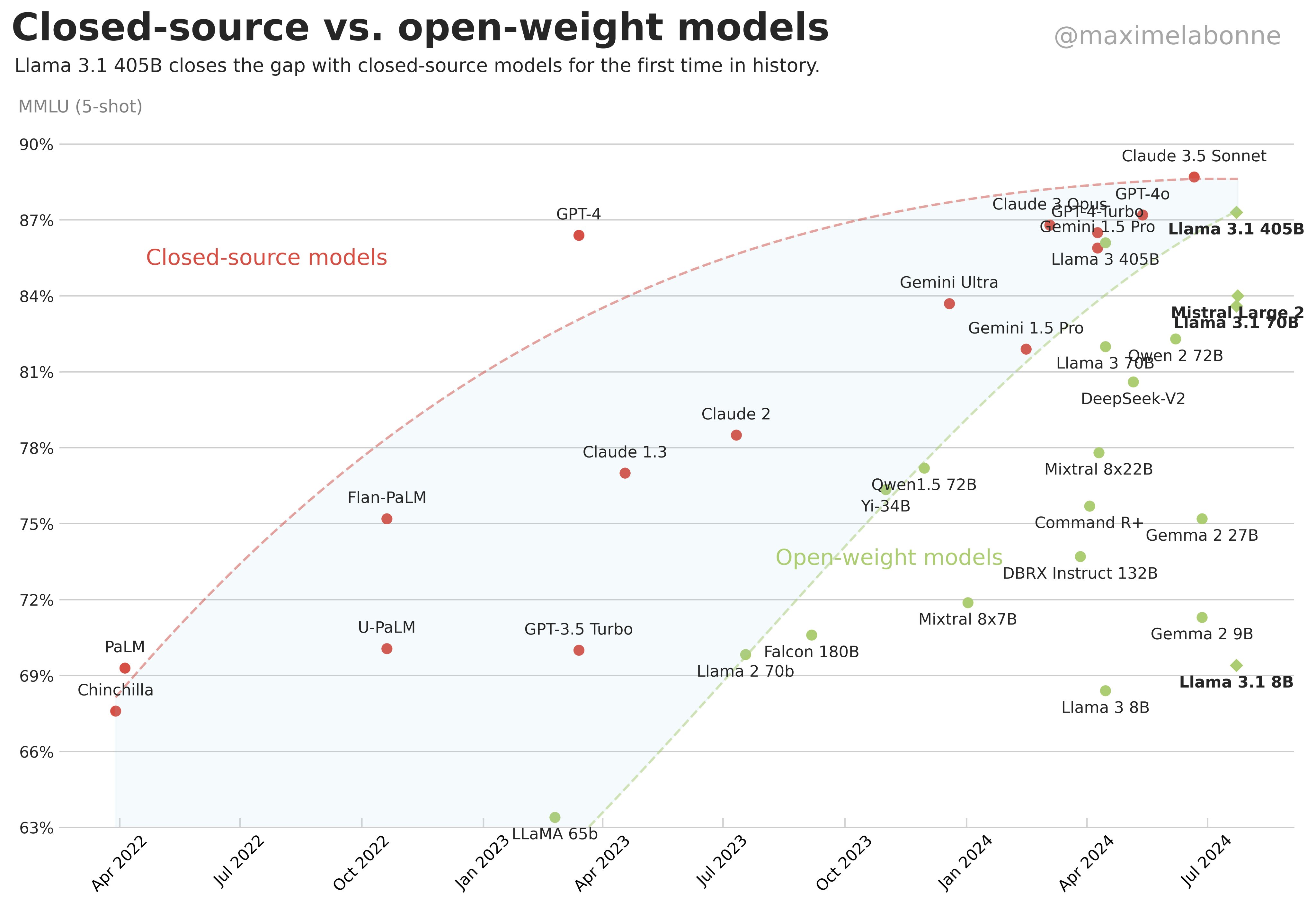
Figure 1 shows the consistent trend of improvement in open- and closed-source models. While I could spend this whole post writing just about his graph, for now just notice the general trend of improvement on MMLU 5-shot benchmark performance over time.
🎉 The Hype is Alive
20 months ago, “ChatGPT is a revolution, the most powerful model ever made,” and today, you can run a model more preferred than this literally on a toaster!🍞 (Schmid 2024)
The quote from HuggingFace Technical Lead Philipp Schmid references Gemma-2-9b-it which, as of August 2nd, ranked 47th on HuggingFace’s language model benchmark – higher than GPT-3.5-Turbo-0613. Gemma 2 includes four different models (see Schmid et al. 2024 for full model details):
- gemma-2-9b: Base 9B model.
- gemma-2-9b-it: Instruction fine-tuned version of the base 9B model.
- gemma-2-27b: Base 27B model.
- gemma-2-27b-it: Instruction fine-tuned version of the base 27B model.
Thus, a 9 billion parameter model bested a 175 billion parameter model. The astute reader will note that Schmid must have the most advanced toaster ever to run Gemma 2 🤣.
📈 Moore’s Law is Dead?
The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin. The ultimate reason for this is Moore’s law, or rather its generalization of continued exponentially falling cost per unit of computation. (Sutton 2019)
Sutton’s famous 2019 blog post1 “The Bitter Lesson” (Sutton 2019) indicated the primacy of computational power2 in improving model performance over time rather than building expert knowledge into the models. However, as we approach the physical limits of transistors on a chip, maintaining Moore’s law has become impossible.
When I first read “The Bitter Lesson,” I thought Sutton argued that engineering work on models did not matter; I was wrong. The key lesson I now extract from my experience, the academic literature, and “The Bitter Lesson” is that model architectures must optimize their use of computation. For example, the introduction of self-attention mechanisms in Transformer models allowed each token to attend to every other token in the input sequence, leveraging parallel computation to process large amounts of data efficiently. Similarly, architectures like convolutional neural networks (CNNs) capitalize on the spatial structure of data, using shared weights and local connectivity to optimize computational efficiency and scalability. These architectures do not merely rely on hand-crafted features but instead exploit the raw power of computation to learn and generalize from massive datasets.
The lesson here seems clear: the architectures that thrive are those that best adapt to and utilize the growing computational resources available.
💾 Limitations on Available Data
The current trend of scaling language models involves increasing both parameter count and training dataset size. Extrapolating this trend suggests that training dataset size may soon be limited by the amount of text data available on the internet. (Muennighoff et al. 2023)
Architectures need to be efficient because of the massive amount of data used during training. Several papers including Muennighoff et al. (2023) note how we are reaching the limits of available data generated by humans. Thus, other authors have investigated training on AI-generated data Shumailov et al. (2023) with mixed results.
If we cannot solve the data bottleneck, relying on more computation will not close the performance gap between state-of-the-art models and general intelligence.
The Future of Language Models
⚙️ A Focus on Efficient Performance
Like Gemma 2, which I discussed (and OpenAI’s Turbo models before it), there is an increasing focus on efficiency and inference speed as we begin to see plateaus in language model performance. Similarly, Mistral Large 2, the second generation of the startup’s flagship model, was announced with a post entitled “Large Enough.” The model is designed to “push the boundaries of cost efficiency, speed, and performance” (MistralAI 2024).
I am not saying this is a bad push. I intend to devote an entire post to the technical innovations that have driven the gains in efficiency and inference speed we have seen in these models. However, I do not believe these technical innovations will lead to the future of AI models.
🛝 A Paradigm Shift is Needed
Language models have the following high-level flaws as I see it:
- A coupling of knowledge and reasoning3 capabilities.
- This is most similar to the issues that the engineers behind models like Gemma 2 seek to address. It’s difficult to train a small model with high-level reasoning capabilities when its weights have to hold so much information in them.
- There is a growing literature on grounding language models with “World Models.”
- There is no concept of thinking deeply, i.e. more inference compute doesn’t get you a better answer.
- Even if we stop improving our chips, we are building far more of them than ever before. Thus, if we had a model that had reasoning capabilities grow with inference compute, that model could answer difficult questions given enough resources.
I believe that to achieve the next level of AI-based intelligence, a new approach that addresses at least one of these flaws is needed.
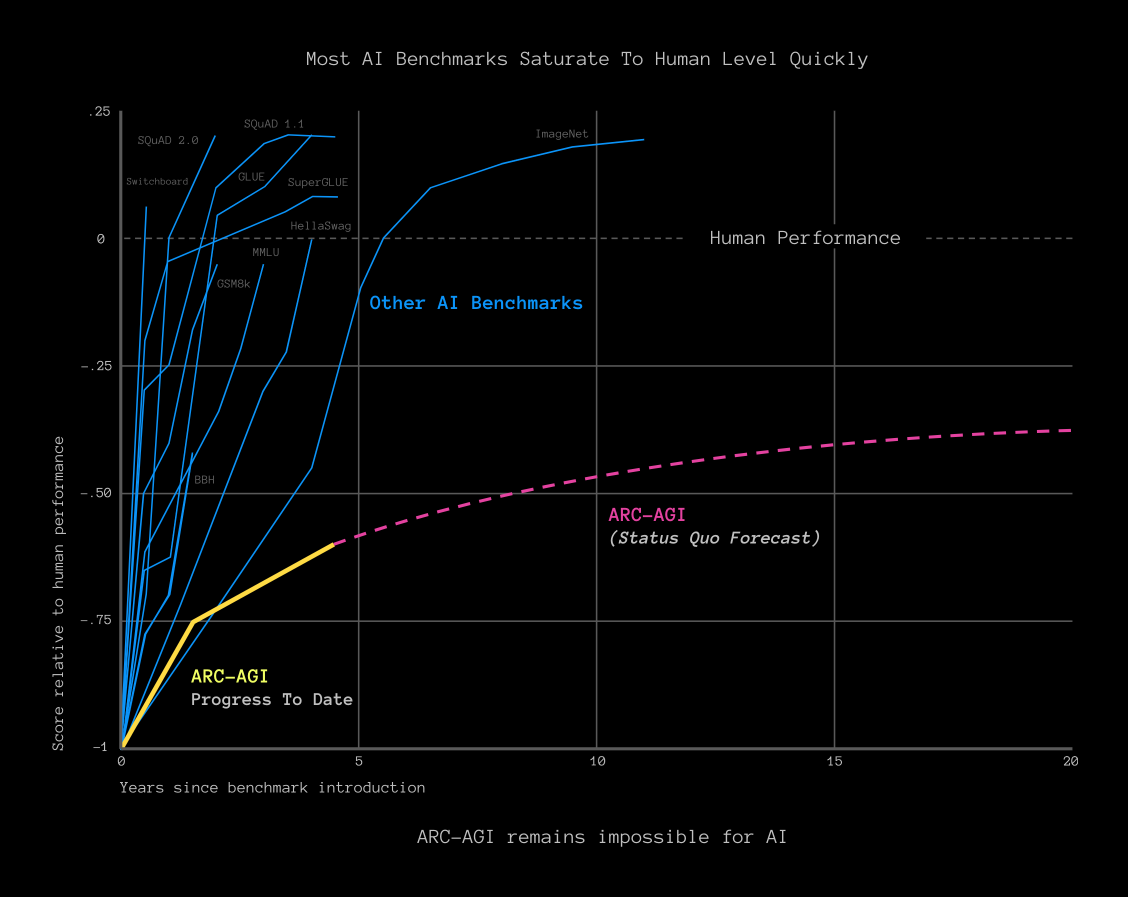
Much of the discussion of performance in this post has been based on benchmarks, a fascinating topic in its own right. Benchmarks have been instrumental in the advancement of NLP all the way back to the GLUE benchmark (Wang et al. 2018), however, they can cause research to become myopically focussed (Gehrmann et al. 2021) or mischaracterize the rate of progress as demonstrated in the paper from Schaeffer, Miranda, and Koyejo (2023) which won the priced Outstanding Paper award at NeurIPS 2023. Figure 2 is a demonstration of one potential flaw from the team at the Arc Price.
🍒 A Final Word from Yann Lecun

If you are a student interested in building the next generation of AI systems, don’t work on LLMs (Yann LeCun [@ylecun] 2024)
Yann Lecun, a famous and foundational NLP researcher, has had some famous pronouncements in the past like in Figure 3. Recently, he has been arguing that LLMs are not the solution to the intelligence problem despite their truly awesome performance.
References
Footnotes
Sauerwein (2024) has a good post covering the summary of “The Bitter Lesson” and related responses.↩︎
Moore’s law observes that the number of transistors in an integrated circuit roughly doubles every two years. Roser, Ritchie, and Mathieu (2024) have a great post visualizing it.↩︎
“Reasoning” is a tricky term to nail down. Here I am referring to current benchmarks rather than more advanced tasks like planning. Planning is an extremely interesting capability that is essential for language-model-based agents. Check out the NeurIPS 2023 workshop on “Foundation Models for Decision Making” for a taste of this research (Yang et al. 2023) as well as Valmeekam et al. (2023).↩︎